I spent some time experimenting with multi-modal model (also called vision models on the ollama site) to see how they perform.
You try these out with the CLI ollama run <model> but I opted to use the ollama Python client.
I didn’t find explicit documentation in the README on how to pass images to the model but the type hints in the code made it pretty easy to figure out and there are several examples around Github. The docs also note the client is modeled around the REST API which has an example request using an image.
I wrote the input validation for the following code with the assistance of claude-3.5-sonnet in Cursor, which blew me away, adding the array of the models that I just installed for validation.
The final code looked like this
import os
import sys
import ollama
PROMPT = "Describe the provided image in a few sentences"
def run_inference(model: str, image_path: str):
stream = ollama.chat(
model=model,
messages=[{"role": "user", "content": PROMPT, "images": [image_path]}],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)
def main():
if len(sys.argv) != 3:
print("Usage: python run.py <model_name> <image_path>")
sys.exit(1)
model_name = sys.argv[1]
image_path = sys.argv[2]
if not os.path.exists(image_path):
print(f"Error: Image file '{image_path}' does not exist.")
sys.exit(1)
valid_models = ["llava", "llava-llama3", "moondream"]
if model_name not in valid_models:
print(f"Error: Invalid model name. Choose from: {', '.join(valid_models)}")
sys.exit(1)
run_inference(
sys.argv[1],
sys.argv[2],
)
if __name__ == "__main__":
main()
I ran each model on this image from the game Sonnet 3.5 built for me.
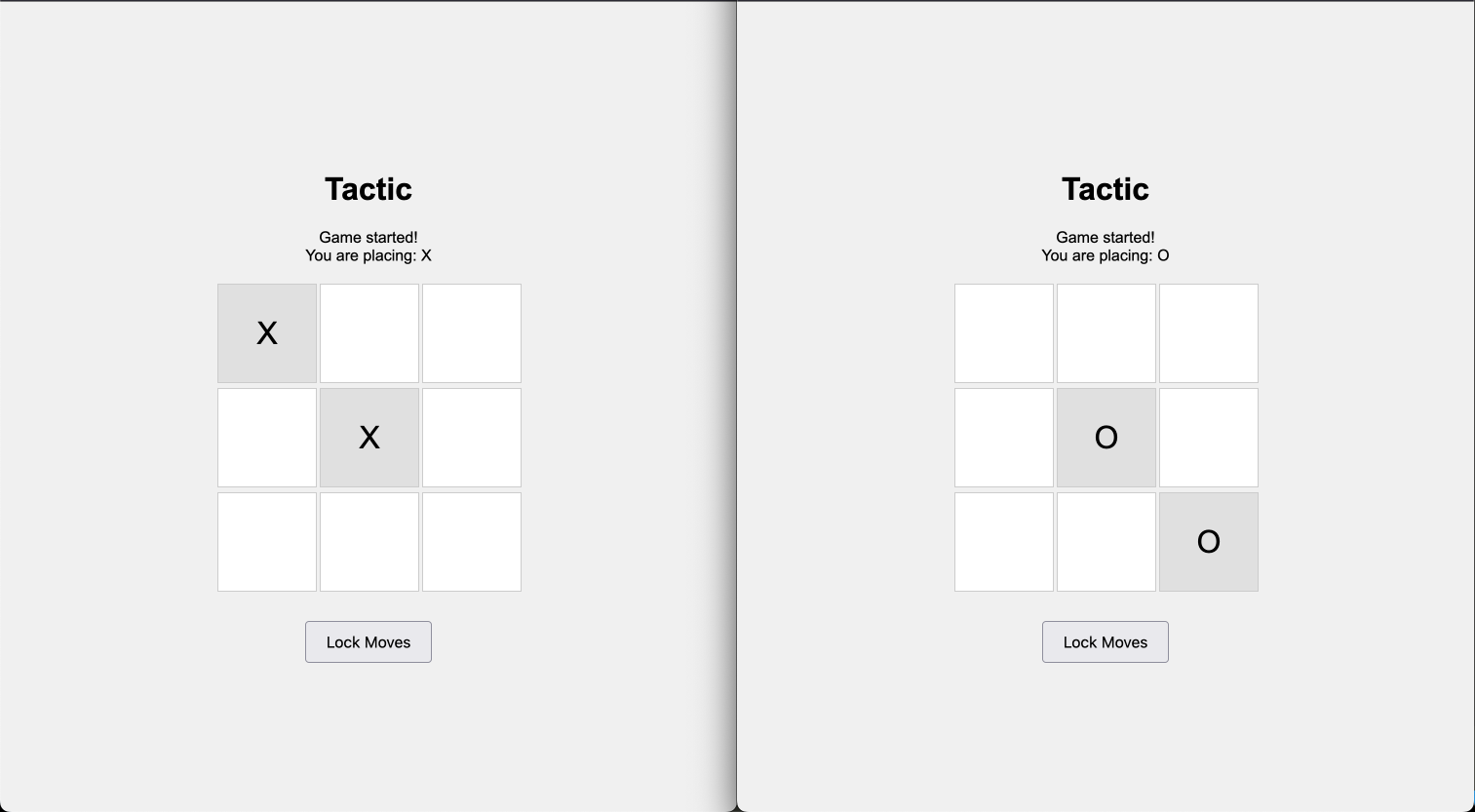
I pulled down the image locally since that is what ollama requires.
Here are the outputs for the four models I tried.
moondream
A computer game interface displays two options for a player to choose from: “Tactic” and “Combat”.
llava
The image shows a comparison of two puzzle games. Both games involve the same pattern, where a square is split into four smaller squares. On the left side of the image, there are four smaller squares, each containing another smaller square within it, creating a nesting effect. On the right side, the game pieces have been rearranged differently from the original arrangement on the left. The objective of the puzzle appears to be to match the arrangement of the game pieces with the original pattern. At the bottom of the image, there is text that reads “TÁCITO,” which translates to “SOLVE” in English.
llava-llama3
Two squares that say X and O with the words Tactics on each.
llava-phi3
The image presents two identical white boxes, each containing a gray letter and a black number. On the left box, there’s a gray ‘X’ paired with a black ‘1’, while on the right box, a gray ‘D’ is accompanied by a black ‘0’. The word “Tactic” is written in bold red text at the top of each box. Below this text, there are two more words: “Ask Moves”, located directly below “Tactic”, and “Solve Moves”, positioned under “Ask Moves”.
For posterity, here are the exact model version I ran these against
❯ ollama list
NAME ID SIZE MODIFIED
llava-phi3:latest c7edd7b87593 2.9 GB 17 seconds ago
moondream:latest 55fc3abd3867 1.7 GB 21 hours ago
llava-llama3:latest 44c161b1f465 5.5 GB 21 hours ago
llava:latest 8dd30f6b0cb1 4.7 GB 21 hours ago
These are pretty small models and the outputs are directionally correct, but I wouldn’t rely on these to get details correct, at least, given what I am seeing in these experiments.