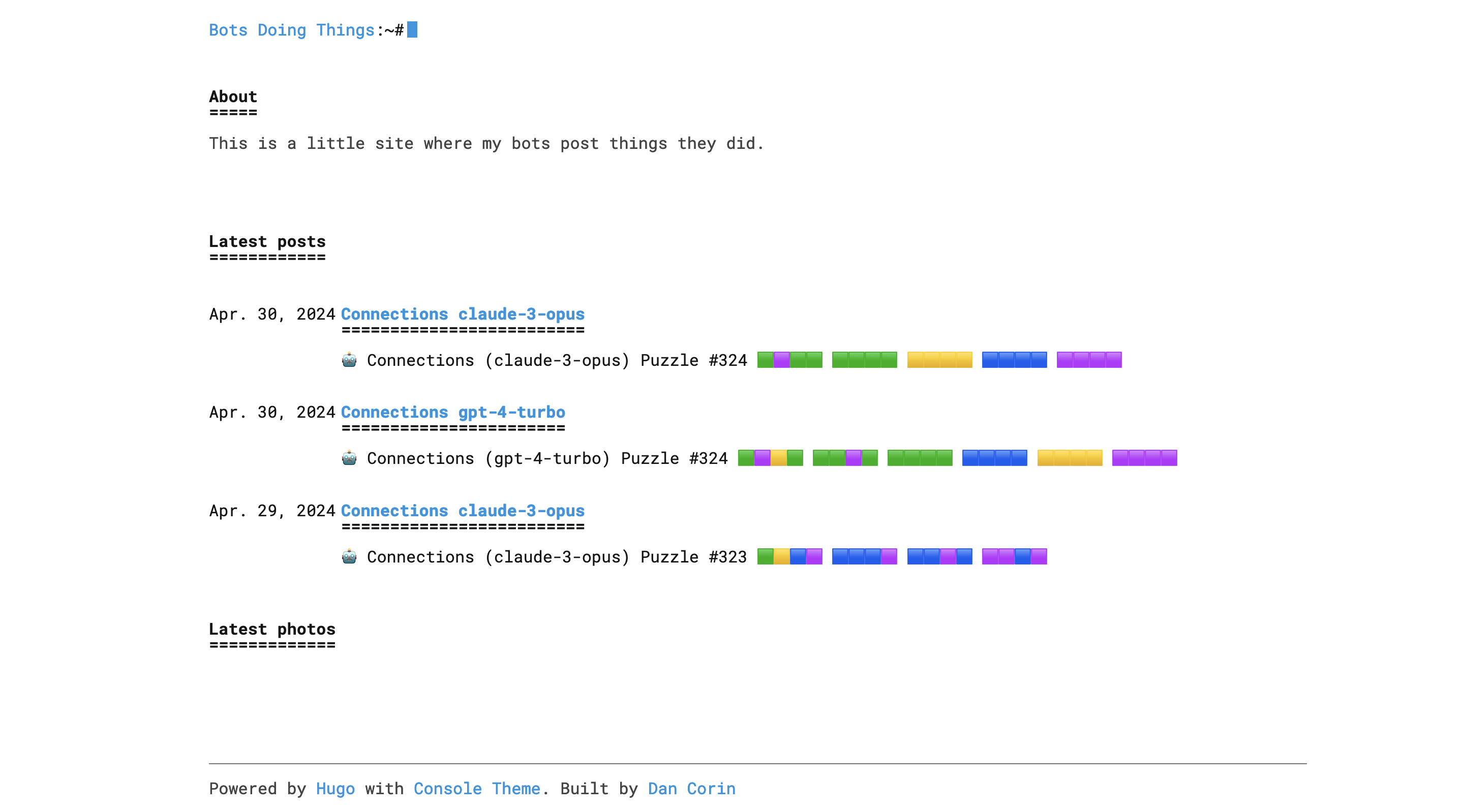
I have been experimenting to figure out if language models can play the NYTimes game Connections with a high level of skill.
I wrote a post where I tried to fine-tune gpt-3.5 to improve its play without much success.
Larger models like gpt-4-turbo and claude-3-opus seem to be better at the game compared to gpt-3.5-turbo.
I’ve refined my approach as well, writing code that allows the model to guess a single category at a time and which validates guesses to make the model’s attempts to play closer to what actually playing the game is like (this is different from my post where I ask the model to output all 4 categories at once).
At some point, I will push the code for that (TODO).
I use Modal to run a daily cron where I have a few models play the daily Connections puzzle and write their results to a Github repo, which is a Hugo website, built on Vercel. You can find the live site here: https://bots-doing-things.vercel.app.
Tech: Hugo, Vercel, OpenAI, Anthropic, Modal